
メタバースプラットフォーム「cluster」のプラットフォーム事業部インフラチームの佐藤です。
clusterではクリエイターの皆様が創造力を発揮できるよう、またユーザーの皆様がよりclusterでの体験を楽しんで頂けるように日々機能開発、改善を行っています。これらの開発、改善を行う際の指標としてWebやアプリでのユーザーの機能の利用状況などのデータ収集を行っています。
このデータ収集基盤は社内では「Panama」というプロジェクト名で運用されています。
様々な場所で発生した大量のデータが集まり、次にデータを必要とするアナリティクスチームなどに届けるための中継点になれるよう、物流の要所であるパナマ運河にあやかってPanamaという名前がつけられました。
今回はこのデータ収集基盤「Panama」の仕組みについて解説します。
背景とコンセプト
clusterでは過去にUnity Analyticsを利用してデータ収集を行っていましたが、一時間あたり100イベントまでの制限や、データが参照可能になるまで数日かかる場合があるなど、ユースケースに合わない事が多かったこと、またUnity以外のブラウザでのイベントを収集し分析に活用したいなどの機運の高まりから、2023年よりGoogle Cloud上に構築した独自のデータ収集基盤を利用しています。
このデータ収集基盤は次のコンセプトで作られています
- 様々なクライアントから発生するデータを収集するため接続が容易
- イベントなどでスパイクする事は日常的なので急な負荷上昇にも耐えられる
- 信頼性が高く障害時の復旧も容易
以下の図を元にデータの受信からDWHとして利用しているBigQueryでデータが格納されるまでの流れを説明していきます。
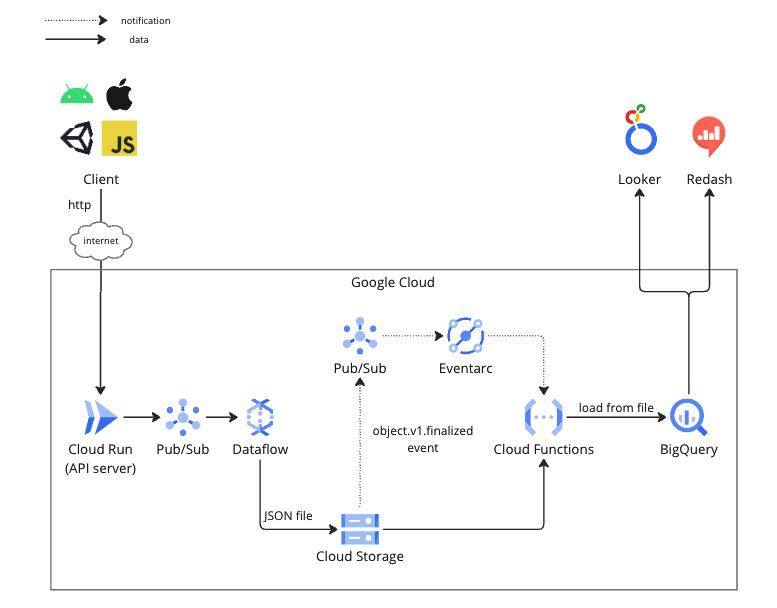
Cloud Run
まずはデータの発生元からイベントデータをサーバーで受け取るためにエンドポイントが必要です。
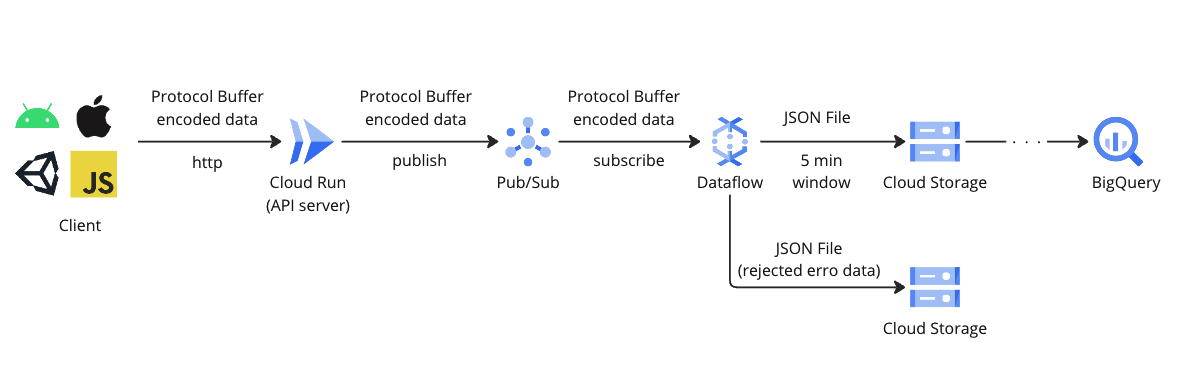
clusterはスマホ・PC・VR機器など様々なプラットフォームに対応したクライアントがあるため、汎用的で確実性の高いWebAPIでデータを送信する方式を採用しています。
このAPIはGoogle Cloudのフルマネージドのサーバーレス実行環境であるCloud Runで構築しています。Cloud RunはDocker imageをデプロイするだけでスケーラブルなAPIを用意することができるので運用も簡単です。APIで受け取ったデータはフォーマットチェックと、イベント毎のIDやタイムスタンプなどのメタデータの付与を行いPub/Subに送っています。
tips
Cloud Runで作ったWebAPIのエンドポイントは新しいコンテナへの変更やデプロイや設定変更の毎にエンドポイントのドメインが変わってしまいクライアント側からは扱いづらいです。そこでドメインを固定する方法が2つ用意されています。
- カスタムドメインを設定したロードバランサーでリクエストを受けCloud Runをバックエンドとして設定する
- Cloud Runのドメインマッピング機能を利用する
どちらの方法であってもプレビュー版なのでSLAの対象外です。clusterではデータ分析用のデータ収集にのみ利用するため、SLAの対象外であることは許容してドメインマッピングの機能を利用しています。
Pub/Sub
クライアントからCloud Runで受け取ったデータはPub/Subにパブリッシュされるようになっています。
Pub/Subは非同期のメッセージングサービスで、レスポンスタイムを重視するAPIサーバーと、大量データ処理に特化しているため急なスパイクに対応しづらいDataflowの間でデータのバッファリングを行っています。またPub/Subはパブリッシュされたデータをデフォルトで7日間保存しているのでDataflowの障害やアップデートのためのダウンタイムにも対応しやすく運用の柔軟性があります。
Dataflow
Pub/Subでバッファリングされているデータはストリーミング処理基盤であるDataflowでサブスクライブして、データのバリデーションやBigQueryへロード可能なJSON形式に変換を行っています。変換を行ったデータは5分毎にファイルにしてCloud Storageへアップロードしています。また異常データについても同様に5分毎にファイルにしてCloud Storageにアップロードしています。
Cloud Functions
Cloud Storageにファイルが作成されたことをトリガーにしてCloud FunctionsでファイルをBigQueryにloadしています。このトリガーの仕組みはCloud Storage → Pub/Sub → Eventarc → Cloud Functionsの流れで通知されます。一見複雑そうな仕組みですが、実際はCloud Functionsの実装時にCloudEventを使うようにコード上でハンドラを書いて起動時のパラメーターで受け取りたいイベントを指定するだけでPub/SubやEventarcの作成のプロビジョニングまでやってくれるので明示的なインフラの設定などは不要です。
BigQuery
デフォルト設定のPub/SubやCloud Functionsはat-least onceのためBigQueryに重複したデータが入る可能性があります。Cloud Functionsからは日付でパーティショニングされたテーブル(社内ではrawテーブルと呼んでいます)にファイルをロードし、データの利用者へはMaterialized Viewで重複削除を行ったViewを公開しています。BigQueryのMaterialized Viewは自動的に差分のあるパーティションのデータのみ再集計されるので、時系列で登録されるイベントデータは効率よく重複削除することができます。
tips
clusterのデータ収集基盤ではエラーデータの再投入や障害時のリカバリを容易にするため一度Cloud Storageへファイルとして書き出した後にCloud FunctionsでBigQueryにロードしています。デメリットとしてファイルにまとめるwindowの時間の分、データの発生からBigQueryで参照可能になるまで遅延が発生します。clusterでは異常検知などは別の仕組みで行っておりデータ収集基盤のデータは分析用途にしか使用していないためこの遅延は許容しています。よりリアルタイムを必要とする場合はDataflowからBigQueryへのStreaming insertなどを検討してみると良いかもしれません。
まとめ
Google Cloudのオートスケール対応のサービスやサーバレスサービスを組み合わせて、可用性が高く保守性も良いデータ収集基盤を構築する事ができました。
Panamaの運用開始から処理可能なデータ量の制限が無くなった事でより解像度の高い分析を行う事が可能になり、収集するデータの種類や量は増えていますがclusterのPanamaでは荷物が詰まったりすることもなく日々データを運んでいます。