
こんにちは、クラスターでSoftware Engineerをやっている あのりく (@anoriqq) です!去年の今頃に私のインターンにまつわるブログを書きましたが、今年から正社員として改めてWeb API Serverの開発をやっています!ありがたいことにプロダクトに使う技術の選定からリリースまでに関わることができたので、この経験をネタとしてブログにしました。ぜひお付き合いください。
clusterは2022年9月のアップデートで、以前よりあったワールド検索機能の品質を改善するリリースを行いました。
お待たせしました!
— cluster公式∞ (@cluster_jp) 2022年9月9日
ワールド検索の性能が向上しました!
公開後にヒットするまでの時間が大幅に短縮したほか、精度も大幅に向上しました🎉
ぜひ検索を利用して、色々なワールドに遊びに行ってみてください💁 https://t.co/e9IenO6Vc9
このアップデートでは、UIの変更は行わずに、APIサーバー内部の変更を行いました。 具体的にはAlgoliaという検索SaaSを導入しました。
当記事では、Algoliaの導入を振り返って、導入の経緯、検索機能の設計全体像、技術選定からリリースまでに苦戦した点をピックアップしてご紹介します。
私自身にとっては、プロダクトの中で横断利用 & 数年以上使い続ける前提の技術選定をする、初めての経験でした。私に似た状況にいる方や、Algoliaの導入を考えている方の助けになれば幸いです!
Algoliaの導入経緯
まずはじめに、clusterのワールド検索機能についての概要を簡単に紹介します。
これまでのワールド検索機能は、Google Custom Search APIを使って実現していました。そして現在では、冒頭にもあるようにAlgoliaを利用して実現しています。
Google Custom Search APIは、検索の対象とするコンテンツがインターネット上に公開しているWebページとして存在し、さらにインデクシング(検索インデックスの更新)にリアルタイム性を求めない場合に選択肢になると思います。clusterではこれらの制約を満たす上、インデクシングのことを考えなくて良い分、比較的導入が容易なため採用されました。ワールド検索機能リリース当時は社内外からの要望が多く、早急にリリースするモチベーションが存在したため、簡単に検索機能を導入できるというのは重要でした。
しかしこの度、当時リリースが予定されていたワールドクラフトストアの商品検索など、より正確で柔軟な検索の需要が増えたこともあり、Google Custom Search APIを卒業し、新たな検索機能を提供することになりました。
AlgoliaはSaaSとして検索APIを提供しています。インフラを考えることなくスケーラブルで柔軟な検索が行えるため採用することにしました。他の理由としては、社内にAlgoliaの利用経験があるメンバーがいたためある程度の知見があったことや、豊富な時間と人員の確保が難しい中で検索基盤のような規模が大きくなるシステムの作成を避ける意図でElasticsearchなどを選択しなかったことが挙げられます。
検索機能の全体像
実際の設計の概要を簡単に解説します。
インデクシング時のデータの流れは以下の図のようになっています。
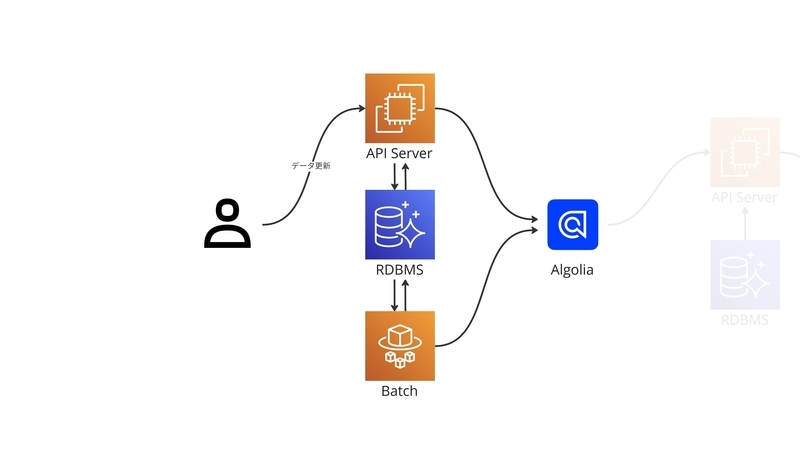
Algoliaの検索インデックスを更新するトリガーは、ユーザーがワールド情報を追加・更新するなどの操作を行ったとき、それから、ワールドの合計入室数などの統計情報を更新するバッチ処理が動いたときの2つです。
検索時のデータの流れは以下の図のようになっています。
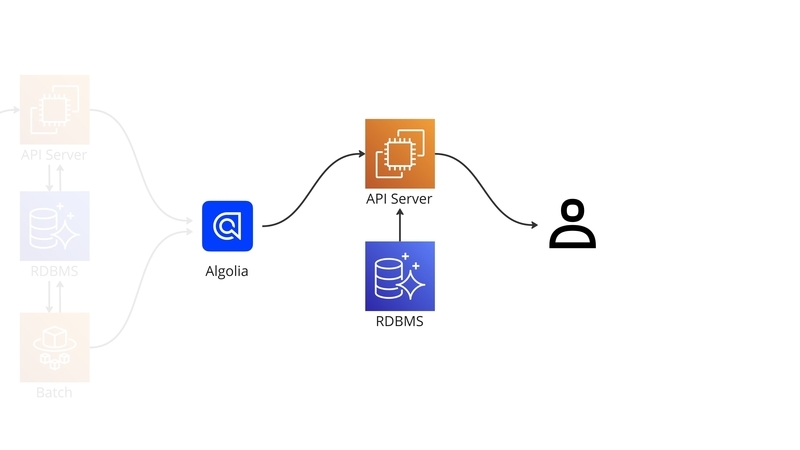
Algolia公式ではエンドユーザーのClientから直接Algoliaの検索APIを呼び出すことを推奨しています。 対して我々は、clusterのAPI Serverを経由してAlgoliaの検索APIを呼び出しています。今回は、Algoliaの検索インデックスに非公開ワールドなどの、検索結果に表示できないコンテンツも含める設計を採用しました。ですので、これらを確実にフィルタリングできるようにRDBMSを参照する構成となっています。
苦戦したこと+改善案
実際に導入するときにいくつか苦戦したことがありました。この章では、epicごとに実施している振り返りで挙がった苦戦したこととそれを改善できないか検討した話を紹介していきます(epicについては以下のTech Blogをご覧ください)。
設計・開発全般の話も含まれるので、Algoliaの導入を検討している方のみならず、なにかの役に立てば幸いです。
有用な費用の試算が開発終盤になり手戻りのリスクがあった
ワールド検索の品質改善を行うことになったとき、まずはどのような方法で改善するのかを検討しました。その中でAlgoliaがclusterに導入できるかどうかの観点で技術調査を実施しました。例えば、今後必要になる機能が実現できるかどうかや、制限事項が厳しすぎないか、利用規約に反しないかなどの観点です。しかし、費用については、Algoliaの料金体系とGoogle Custom Searchより費用を抑えられる見込みがあるかどうかの調査はしたものの、実際の運用で、どの程度の費用になるか検討しなければいけないところの考慮が漏れていました。そのため、開発を進めてから予算を超えることが分かって設計を見直さなければならなくなるなどの手戻りのリスクがありました。
具体的な費用の見積もりが行われたのは開発終盤になってからでした。この状態では、開発は進めたものの費用が原因で導入を見送ったり、機能を削らなければいけないなどのリスクがあります。理想的には、設計初期から、検討中の設計でどのくらいのコストがかかるかを並行して見積もりたいです。
改善点としては、技術調査で料金体系を把握しておき、設計時はコスト観点も常に持って設計を判断できる状態にするのが良さそうです。そのためにも、最初の技術調査で、設計次第では費用が大きくなりすぎる可能性があることを明示しておくなどの対応が考えられます。
Algoliaの利用料金は、検索リクエストの合計と、レプリカインデックスを含む全インデックスの合計レコード数の2つの要素によって決まります。前者の検索リクエストの合計は、サービスのユーザー数や、過去の検索機能の利用数などから予想ができますが、後者の合計レコード数は設計によって変わります。ですので、どのインデックスにどのような情報を登録するのかや、レプリカインデックスはどんな基準で作るかなど、合計レコード数に関係する設計をする際は、コスト面でも問題がないかを忘れずに確認すると、手戻りのリスクを減らすことができます。
既存データを検索インデックスに登録する方法に悩んだ
ワールド検索にAlgoliaを導入する時点で、すでに多くのワールドがclusterに存在していたため、ワールド検索品質改善のリリースより前にそれらすべてのワールド情報をAlgoliaの検索インデックスに登録しておく必要がありました。そこで今回は、任意の方法で抽出したワールドをCSVファイルとして入力し一括で検索インデックスに登録するリクエストを作成するCLIを作成しました。
一括で更新する機会はリリース前の1度以外は基本的にはないと予想したことと、将来機会があっても何も考えずに一括更新すればよいケースもありますが、それができないケースの可能性も考えられることから、使い捨てる想定でCLIを作成する選択をしました。
検討はしたが採用しなかった方法としては、次のようなものがありました。
リリース前に限らず、全レコードをインデックスに登録するジョブやAPIを用意する
- レコード数が多いため、このバッチ処理実行時にその他のリクエストがレートリミットにより失敗してしまう懸念がある
- 差分だけ更新するのも検討はしたが、”リリース前に全ワールドをインデックスに登録する”という目的の割に複雑な設計になってしまう
ユニークIDを指定して対象をインデックスに登録するAPIを用意する
- あまりにも多いユニークIDを指定する運用は現実的ではなく何度かに分けて実行することになりそうなど、運用が難しいだろうという懸念がある
個人的には、ソフトウェアを作っていると長く使われるものを作りたくなる気持ちがありますが、今必要な機能が将来にわたっても必要なのかどうかを念頭に置いて、コストに見合うものを作る判断をすることが大事だなと実感しました。
インデクシングリクエスト冗長化すべきか悩んだ
Algoliaが高可用性を謳っていることからも分かるように、Algoliaへのリクエストはほとんど失敗しないことが、事前の検証で分かっていました。想定されるエラーはネットワーク起因の問題でリクエストが通らないケースが主です。
初期の設計では、cluster側のAPI ServerとAlgoliaとの間にQueueを挟んでリクエストを送信することも考えていましたが、リリースした設計にはそのような冗長化は施さずにAlgoliaへリクエストを送信しています。
ほとんど失敗しない処理にかけるコストとメリットを天秤にかけてこのように判断しました。最終的には、ユーザーさんのコンテンツが公開されてから最速で検索できるようになる構成になったので、それらコンテンツが多くのユーザーさんの目にとまる可能性を上げることができました。
外部サービスを使う際は、どの程度信頼するかどうかの判断が難しく、一律信頼しない側に寄せたほうが楽で安心できるところもあると思います。過去のインシデント発生率などを確認し、コストを掛けて冗長化するのが見合うかを判断すると良さそうです。
検索APIのページングインターフェース定義に苦戦
clusterのAPIサーバーを介してAlgoliaの検索結果を利用する設計上、clusterのAPI側でもページングを行うためのインターフェースを定義・実装する必要がありました。
AlgoliaのSearch APIが提供するページネーション機能は、page / hitsPerPageを指定する方法と、offset / lengthを指定する方法の2種類が提供されており、Algolia公式には前者の利用を推奨しています。我々はこれらを使ってページングに対応したAPIを定義しなければなりません。
しかし、我々にはいくつかの課題がありました。API ServerからAlgoliaへ検索リクエストを行い、その検索結果をもとにRDBMSからワールド情報を取得・フィルタリングするという設計を採用したため、RDBMSの更新直後などは、Algoliaのインデックス更新が完了していない状態が発生します。そうすると、AlgoliaがAPI Serverに返却するワールドリストと、API ServerがClientに返却するワールドリストが異なる場合があります。
例えば、ワールドを非公開に変更した場合、clusterのRDBMSでは即時非公開状態になりますが、Algoliaのインデックスは即時反映できません。ですので、長くとも数分の間はAlgoliaの検索APIの結果に非公開にしたはずのワールドが含まれることになります。
上記のような事象は、ワールドの特定の設定を変更したタイミングとそのワールドが検索結果に含まれる検索クエリを実行したタイミングが重なった場合という特定の状況下で発生することに加え、APIで指定した件数分の結果を返せない場合があるというだけで表示すべきユーザーさんのコンテンツが欠け落ちることは無いため、今回は許容することにしました。
今後、より頻繁に更新されるインデックスから検索するAPIを設計する場合や、ワールド数やワールド検索機能の利用者数の桁が増える場合は、トークンベースのページングを行うなどclusterのAPIとAlgoliaのAPIの間のインターフェースの差分を吸収する仕組みの導入を検討予定です。
おまけ
clusterのAPI ServerではGoを主なプログラミング言語として採用しています。Algoliaから公式に提供されているAPI ClientにはGoのパッケージもあるので、今回はこれを利用しました。このパッケージを使ってみたことで分かったTipsをいくつか紹介します。
ctxを第一引数ではなく第二引数以降 (interface{}型) のoptionとして渡すインターフェース
Algoliaのインデックスからレコードを検索するときのメソッドSearchなどが、context.Contextを第二引数以降で受け取るインターフェースを提供しています。Goではcontext.Contextを第一引数で受け取る慣習がありますが、AlgoliaのAPI Clientはそうなっていないのでctxを渡し忘れたり、レビュー時に読み替える手間が発生しました。
clusterでは下記のようにwrapして使っています。
func Search(ctx context.Context, q string, opts ...interface{}) (res, error) { return index.Search(q, ctx, opts...) }
opt.Filters()は最初のひとつだけが適用される
Queryの他に、検索結果を絞り込む機能としてfiltersオプションがあります。検索時のフィルター条件を動的に指定したい場合に、検索時に渡すオプションの組み合わせを切り替える案はうまくいきませんでした。opt.Filters()を複数渡した場合は最初のひとつだけが適用され、以降は無視されます。
そのため、条件式の文字列自体をいい感じに生成する必要がありそうでした。
たとえば以下の1つめのような指定をした場合は第一引数のopt.Filters()以外は無視されます。2つめのように式で指定しなければなりません。
func main() { // Bad) "type:Food" のみ適用される index.Search(q, opt.Filters("type:Food"), opts.Filters("price < 1000")) // Good) 式で指定する index.Search(q, opt.Filters("type:Food AND price < 1000") }
value型かつomitemptyのAttributeはPartialUpdateでempty値に更新できない
どちらかというとAlgoliaのAPI Clientと言うよりはGoのencoding/jsonの話ですが、レコードを更新するリクエストを送る際、指定するObjectの型についての話です。
前提として、clusterではObjectの一部Attributeのみを更新するPartialUpdateを使っています。また、どのAttributeの更新でも同じstructの型が使えるように、Objectの定義はインデックスあたりひとつになるようにし、objectID以外のAttributeにはomitemptyを指定しています。
Objectのstructをjsonにencodするときにvalue型のフィールドはempty値だと省略されてしまうのでレコードを更新できなくなります。そこでclusterではObjectID以外の値は基本的にpointer型にしています。
type ObjectFoo struct { ObjectID string `json:"objectID"` Name *string `json:"name,omitempty"` Type *string `json:"type,omitempty"` }
おわりに
検索品質改善の取り組みをきっかけに、Algoliaを導入してみた知見を紹介しました。
私の所属するSocial Teamでは、ユーザーの「楽しいの連鎖」を無限に加速する という目標を共有して日々活動しています。
検索品質を改善することで、ユーザーのみなさんの感情を揺さぶる出会いが連鎖的に広がることを期待しています。
clusterの大きな魅力のひとつは、3D空間での体験を手軽に体験できることです。しかし、無数にあるワールドの中から気に入るワールドを探すのは大変です。我々は、検索品質の改善のみならず、ユーザーのみなさんの新たな出会いが生まれるような取り組みを継続的に行っています。
日々創造され続けるUGC、そこに集まる人々、すべての”楽しい”をつなげるプラットフォームを一緒につくりませんか?