
メタバースプラットフォーム「cluster」のインフラチームの佐藤です。
今回はclusterではログをどのように扱っているかをインフラ観点からご紹介します。
ログは安定したサービス提供を行うために役立つ基本的な要素です。初期の素朴な構成で発生した問題点や、プロダクトの成長に合わせて、より活用しやすいように改善を行なった結果など成果の一部を公開したいと思います。
CloudWatch Logsの限界
現状のログの構成について説明する前に過去のログの運用方法とその課題点などから説明します。以前は以下のように各コンポーネントからCloud WatchLogsにログを送り、何か問題が発生した場合の調査などはCloudWatch Logsに対して直接クエリを実行して調査を行っていました。
インフラ構成としては以下の図の通りです。AWSの各種サービスの代表的な用途としてはECSはAPIサーバーやバッチ処理、EC2はroom server(注1)、Lambdaはファイルのアップロードをトリガーにした処理などを行なっています。
注1: clusterでは3D空間内でのクライアント間の同期に内製のroom serverというサーバーを使っています。詳細はこちらの投稿を参照ください。 https://tech-blog.cluster.mu/entry/2022/04/13/143058
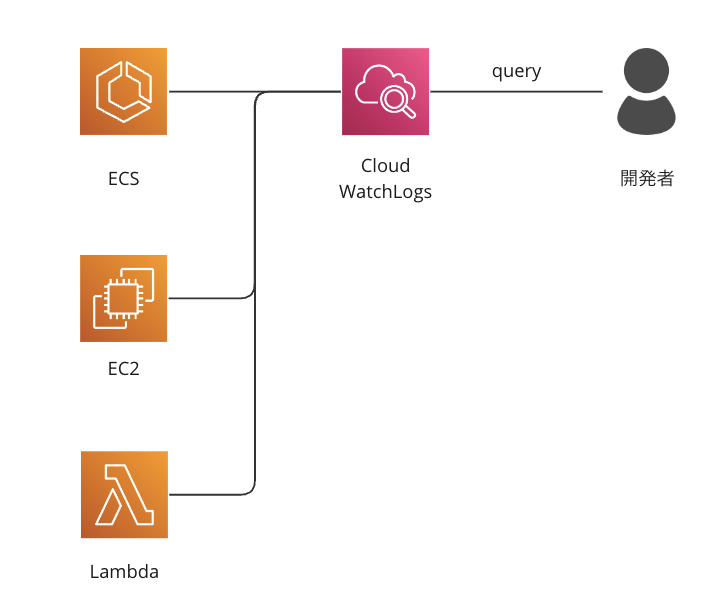
シンプルで信頼性の高い方法ですが一方でCloudWatch Logsはトラブル時などに参照する利用が多いため、都度ログを絞り込むためのクエリの書き方を調べる必要があったり、誰でも利用可能な状態とは言えませんでした。プロダクトを構成するコンポーネントが増え、ログの量、種類共に増加し、伴ってエンジニアも増えてきた際にこのような構成ではトラブル時の対応に時間がかかってしまう問題点が出てきました。
ログのインフラ構成の改善
インフラチームでは前述の課題を解決するためログ関連のインフラ構成を改善することにしました。新しい仕組みで以下の要求を満たすことを目標としました。
- 新しいコンポーネントを追加した際のログの管理が容易であること
- ログが検索しやすい状態になっていること
前者についてはclusterの多くのコンポーネントはAWSの各種サービスを利用して作られているため、一度ログをCloudWtach Logsに送ってそこからログの蓄積、検索用のサービスに転送することにしました。特定のログ転送用のデーモンやエージェントなどを導入する際に送信元と受信先がそれぞれ対応しているかどうかの調査や検証の煩わしさを避けるためです。後者についてはCloudWtach Logsを直接クエリするのではなく、ログをより一般的な全文検索エンジンに保存し検索エンジン上で検索を行うことにしました。
ここまでの計画を単純化して図にすると以下のようになります。

この図ではログが一度ファイルに書き出されていますが、これは検索エンジンの障害時にリトライしやすいように、また一定期間経過したログはCloudWtach Logsからは削除し、このファイルをログの長期的な保存先とするためです。
tips: ログの取得対象がエージェントを導入しやすい環境であったり、ログの転送先の信頼性が十分に高い場合はPromtailやFluent Bitなどで直接、長期保存用のストレージや検索エンジンに送ってしまうのも構成をシンプルにすることができるため良い選択肢かと思います。
構成の説明
ログのファイルへの永続化までの部分
大まかな構成を示したところで、この永続化されたログファイルの前後に分けて構成について詳細を説明していきます。まずはログのファイルへの永続化までの部分の構成図です。

APIサーバーを動かしているECSではFireLensを利用してリクエストログ、アプリケーションログなど用途に応じて異なるLog Groupにルーティングしています。FireLensはAWSの提供しているログルーターですが、使用感としてはサイドカーとして立ち上げたFluentdやFlutnt Bitからログを転送しているような感覚で使えるので柔軟で汎用性の高い仕組みです。
APIサーバーのログを含む各種コンポーネントからCloudWatch Logsに送られてきたログはサブスクリプションフィルターでKinesis Data Firehoseに送ります。CloudWatch Logsのログはログ毎に改行が入っていないためFirehoseでLambdaを使ってログ毎に改行の挿入、ロググループ名などのメタデータを追加した後にS3に保存します。
S3から検索エンジンに送る部分
次にS3から検索エンジンに送る部分ですが、構成としては以下の図のような構成になっています。

後半部分はS3にログファイルが作られたタイミングでトリガーされるイベントを起点に始まります。イベントはSQSに送られキューイングされます。後続のPipelineやOpenSearch自体にも負荷に対する弾力性がありますが、高負荷時や何らかの障害時にはSQSが復旧までの緩衝になってくれます。
次にSQSのキューをOpenSearch IngestionのPipelineがサブスクライブしてOpensearchに登録しています。PipelineではCloudWatch Logのロググループ毎に応じたindexに登録される設定をしてあります。
ここまでの流れで、OpenSearchに登録されたログはWebUIであるOpenSearch Dashboards上で簡単に検索することができるようになりました。
ログの検索、可視化の改善
ここで改めて、ログと関連する構成要素を含めて全体像を見てみましょう。

任意のサービスで発生したログは一度CloudWatch Logsに出力され、最終的にはOpenSearchで検索可能な状態になります。ログはOpenSearch Dashboardsから検索するだけでなく、この図では新たにGrafanaからも検索可能なようにしています。実際のトラブルの際はログだけではなく、メトリック、トレースなどと組み合わせて調査を行うことがあるためGrafanaに常に集約して一元的に参照可能な状態にしています。また、Grafanaでは事前にダッシュボードを作っておくことができるため代表的なログや指標の用意しておくことで、個別のサービスのクエリなどを覚えなくても、ある程度概要が掴める状態にもなっています。
まとめ
まとめです。インフラ構成を改善する際の目標は以下の2つでした。
- 新しいコンポーネントを追加した際のログの管理が容易であること
- ログが検索しやすい状態になっていること
前者は新しくログを取得したいコンポーネントが増えた場合も、CloudWatch LogsにFirehoseへ転送するサブスクリプションフィルターを追加するだけで、OpenSearch Ingestionでロググループ毎にindexが作られるので管理が容易になっています。
後者についてはOpenSearchの導入でログを検索しやすい環境が整いました。またGrafanaの導入でクエリを覚えなくてもダッシュボードから重要なログを見ることができるようになりました。
ログは出力しているものの、うまく役立てられていないなど、よくある課題ではないでしょうか?clusterでは今回紹介したログを含め監視の仕組みなど日々改善を行なっているので、今後も得られた知見など定期的に公開していく予定です。