
クラスター株式会社でSoftware Engineerをしている thara です。
私たちは今年、clusterのシステム分割という重要なプロジェクトを完了しました。この取り組みは、私たちのメタバースプラットフォームの進化と持続可能な成長にとって欠かせないものでした。
本記事では、システム分割の技術的なアプローチとその過程で直面した課題とプロジェクトの結果について説明します。
背景
clusterがリリースされて6年が経過しました。
当初はバーチャルイベントプラットフォームとして展開されていましたが、2020年にはスマホアプリをリリースし、フレンド機能などのSNS機能の他、常設のCGコンテンツであるワールド機能に加え、Unityで作成したマルチプレイゲームを公開できるようにもなりました。
2022年には、cluster上で誰でもワールドを作成できる「ワールドクラフト」がリリースされます。
このように、clusterはリリースして以降、バーチャル空間上の体験を提供するという軸はそのままに、その体験を形を変えて提供してきた経緯があります。
これに伴い、大きく2点の課題が出てきました。
まずは、システムの複雑性の増大です。clusterはroom1 内でリアルタイムに3D空間を共有できるinroom領域と、アカウント管理やroomへの入室するまでの体験などを担うoutroom領域に大きく分かれていますが、双方ともにプロダクトの状況に応じて機能が増減しています。2 これに伴い、内部はその状況に応じた形に変わっていくのですが、ある箇所の変更の影響が他の箇所に出てincidentに繋がったり、ある箇所の変更の影響が大きくて手が出せない、みたいなことが増えてきました。
2つ目として、システム理解の認知負荷の増大が無視できなくなってきた、という点があります。クラスターは年間100人以上採用するなど、急激に組織規模が拡大しています。
この人数は全社スコープですが、当然所属するソフトウェアエンジニアの人数も急速に拡大し、その勢いはいまだに衰えていません。また、2024年卒の新卒採用も開始し、いわゆるジュニアのソフトウェアエンジニアの増加が明白です。
人数が少なくシステムがまだ今ほど複雑でなかった時点では、各々がインフラ構成とコードベースを全て把握できるレベルだったのですが、今はそうとは言えない規模にまで膨らんできていますし、今後も膨らみ続けていく想定です。
解決策
今後、システムも組織も拡大していく中でこの問題をそのままにしておくと、チームとして制御不可能なシステムができてしまい、プロダクトの進化の妨げになる可能性があるのではと考え、clusterを構成するシステムのうち、その責務が明瞭である「リアルタイム空間の共有を担うroomとそれを支える仕組み」を社内SaaS的なサブシステムとして分割することにしました。
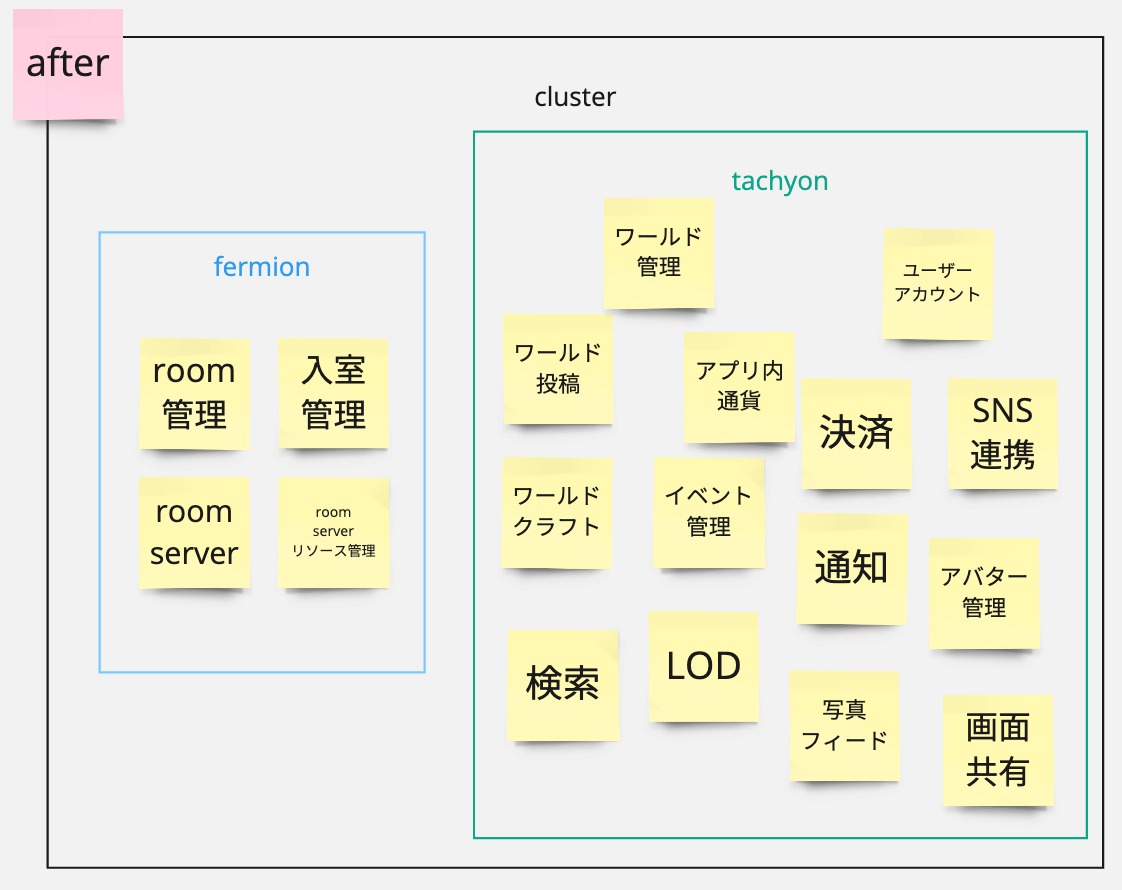
この「リアルタイム空間の共有を担うroomとそれを支える仕組み」を持つ社内SaaS的なサブシステムを社内のコードネームで fermion と名づけ、このfermionを既存システムから分離することを fermion分離プロジェクト として進めることになりました。
fermionが持つ「リアルタイム空間の共有を担うroomとそれを支える仕組み」とは具体的には以下の責務のことです。
- リアルタイム空間の共有を担うroomという概念の定義
- リアルタイム空間の共有を実現するroom serverの提供
- room serverのリソース管理
- roomへの入室管理
また、この fermion を使用する、roomをエンドユーザーにどう提供するかやその他のアカウント管理やソーシャル機能などを担うシステムを tachyon と名づけました。3
fermionは、tachyonとは別の内部サービスとして提供し、tachyonからgRPCサービスを通じてfermionを使用することにしました。

本稿でも以降、 fermion, tachyon と呼称します。
システム分離プロジェクトにおける課題
fermion分離プロジェクトは大規模であり、コードベース的にもアーキテクチャ的にも現在だけではなく将来にも渡って影響の大きいものなので、入念な準備が必要です。
fermionを分離している間にその他の機能開発の妨げになってはなりません。clusterは全プラットフォームに向けて毎週アプリのリリースを行っており、server sideに至っては営業日に毎日リリースしています。また、仮想空間上の生活空間を担う役割もあることから、基本的な方針としてメンテナンス期間を設けることもしていません。
機能開発の妨げにならずにfermion分離を進めるには、他の機能開発から影響箇所を隔離し、影響範囲を局所化する必要があります。また、実際に分離する際にシステムを止めることも許されません。
当然ながら、分離する際にシステムの振る舞いが変わったり、分離完了後にincidentが発生するのも避けなければなりません。
fermionの持つ責務のうち「room serverのリソース管理」というものがあります。
これはfermion分離前も有していた機能ですが、「リアルタイム空間の共有を担うroomとそれを支える仕組み」とは別の概念と密結合していたため、このfermion分離の段階で整理する必要がありました。
また、リソース管理機能は非線形的な挙動であり、動的に変化するリソースの状況を監視・調整する必要があるため、一貫したテストシナリオを作成・実行することが困難であり、同様に分離前後で振る舞いが変わっていないことをどのように検証するかが課題でした。
課題を解消するための実施手法
これらの課題を解決するため、大まかに以下の手法を取りました。
- Gatewayによる隔離
- dual writeによる段階的移行
- dual readによる差分検証
- 状態スナップショットによる差分検証
- 諦めの局所化
以下に、これらの詳細を述べます。
Gatewayによる隔離
Gatewayとは、外部システムやリソースへの相互作用の実態を隠蔽し、外部システムやリソースを扱いやすくするobjectのことです。
今回の場合、「外部システムやリソース」に当たるのは fermion です。
まず、既存のコードベースからfermionの責務に属する知識を fermion API gatewayとして分離するリファクタリングを行いました。これにより、fermion分離時に伴う変更箇所をこのfermion API gatewayに局所化でき、他の機能開発の妨げになることを避けられます。
また、fermion分離後にもこのfermion API gatewayは存続することとし、このAPI gatewayの中がDDDにおけるBounded Context の境界と位置付け4 、fermionのgRPCサービスへのアクセスはこの中に局所化することにしました。
もちろん、このGatewayを抽出するリファクタリングの前には、どの概念をfermion/tachyonで扱うか、どの概念をfermionからtachyonに公開するか、fermionからtachyonに公開するAPIはどのようなものか、などの設計を入念に行っています。そのインタフェースに合わせて、fermion API gatewayを設計・実装し、fermionとtachyonの概念のmappingもそこで行っています。

dual writeによる段階的移行/dual readによる差分検証
dual write/dual readとは、一般的な技術用語ではなく社内用語です(たぶん)。
dual writeとは、2つのシステムに対して同程度の入力を行うことを指します。例として、「RDBのテーブルに対してdual wirteする」とは、1リクエスト内で同程度の意味を持つスキーマの異なるテーブルに対してレコードを作成することを指します。
dual readとは、dual writeと組み合わせて使用され、旧系統のデータとdual writeによって入力された新系統のデータを同時に読み込むことです。その読み込み操作の結果を検証することで、2系統の振る舞いが変わっていないかを検証できます。

これは、Scientistという、以下のGitHub社のブログで解説されているRubyライブラリからインスパイアされたものです。
clusterのserver sideはほぼGoであり、このままScientistを使うことはできないので自前でfermion/tachyonの操作をdual write/readする実装をしました。5

このdual write/readするかの判定には、feature flagを用いて、テスト環境・開発環境・ステージング環境・本番環境それぞれでfeature flagのon/offを切り替えるようにしておき、開発中やQA、リリースなどのフェーズでfeature flagのon/offを切り替えることで、fermion分離と同一のコードベースながら他の機能開発への影響を限定的に分離作業を行えるようにしました。
また、fermion API gateway内部でdual write/readによる分離作業を少しずつ進め、かつ、fermion側のwrite/readで意図せぬエラーが発生した際にシステムの振る舞いとして影響がないようにすることで、メンテナンス期間を設けずに分離作業を完了できるようにしました。
dual write コードイメージ
func (g *fermionAPIGateway) CreateRoom(ctx context.Context, roomID RoomID) error { req := &CreateRoomReq{...} resp, err := g.fermionAPIClient().CreateRoom(ctx, req) if err != nil { // 略 } return nil } func (g *fermionAPIGateway) fermionAPIClient() fermionAPIClient { if featureFlag.FermionSeparationDualWrite { // dual write flag on時には実装を切り替える return &dualWrite{ ... } } return g.fermionAPIOnTachyon // 既存実装のfermion相当の処理を抽出しfermionAPIに適合させた実装 } func (d *dualWrite) CreateRoom(ctx context.Context, req *CreateRoomReq, opts ...grpc.CallOption) (*CreateRoomResp, error) { // 略 (tachonへのwrite/read) // 移行途中で意図せぬfermion側のエラーによってシステムの振る舞いに影響を与えるのを避けるため、 // panic及びfermion API errorを適切に握りつぶし、tachyonにフォールバックする fermionResp, err := panicToError(func() (*CreateRoomResp, error) { return d.fermion.CreateRoom(ctx, req, opts...) }) if err != nil { return tachyonResp, handleFermionError(ctx, err) } // 略 } func handleFermionError(ctx context.Context, err error) error { if featureFlag.FermionSeparationPublishingError { return err } else { clusterlog.CaptureException(ctx, errors.Wrap(err, "fermionAPI failed")) return nil } } func panicToError[R proto.Message](f func() (R, error)) (result R, err error) { defer func() { if perr := recover(); perr != nil { switch e := perr.(type) { case error: err = errors.WithStack(e) // stack traceの付与 default: err = errors.Errorf("%+v", e) } } }() return f() }
状態スナップショットによる差分検証
また、上記のfermion API gatewayのようなシステム間の境界だけでなく、外部からの操作によって変化したリソース管理の状態も分離前後で大きく変わっていないことを検証するために、fermion/tachyonそれぞれのDBからリソース管理状態を示すスナップショットを生成し、定期的にその差分を検証しました。
スナップショットのフォーマットは、1時点でのリソースの集合はデータ件数がそれほど多くないことがわかっていたので、シンプルにJSONとし、差分検証はJSONのdiffを生成するライブラリを用いました。
dual read時の結果の検証も合わせて、差異を検知した場合にはSlackに通知し問題を修正する、といったことを分離プロジェクト中は行いました。

諦めの局所化
システムを分割する際に、プロダクトが置かれている状況から今まで得られた経験からでは、現段階ではいくつかの概念や機能を特定の責務に縛り付けることが難しいことがままあります。
clusterでも先述の通り「どの概念をfermion/tachyonで扱うか、どの概念をfermionからtachyonに公開するか、fermionからtachyonに公開するAPIはどのようなものか」は入念に行いましたが、それでもどうしても現時点では曖昧性を残しておきたいポイントというのは存在します。
完璧なシステム分離を目指して曖昧性を排除するようにする事もできますが、往往にして設計に時間がかかったり、後から概念の見直しを図った際の手戻りが大きかったりなどと、プロダクトの発展には直接寄与しない時間を費やさなければなりません。また、分離プロジェクトの完了までの時間が長くなると他の機能開発に思わぬ影響が出たり、プロジェクトにかける人的リソースが膨らみ続ける、などの悪影響が出かねません。
このfermion分離プロジェクトでは、そのような責務が曖昧なポイントが局所的に存在することをあえて認め、主となる責務が分離できていればプロジェクト完了の条件を満たす、としました。分離プロジェクトとしての完璧さを求めるのではなく、まず終わらせることを第一に考えた、ということです。6
この曖昧なポイントを残す、という決定はいわば「諦め」と言っても過言ではありません。しかし、単に全く手が出ないから見ないふりをする、というものではなく、「この場所は現状のままでも十分に分離プロジェクトの目的は満たせる」という戦略的な判断です。
分離プロジェクト前は責務領域がシステム全体にわたってグラデーションになっていたものが分離プロジェクトを通じて、そのグラデーションを局所化できたとすれば、そのプロジェクトの価値は大いにあると言えるでしょう。
この局所的な「諦め」ポイントへの変更には有識者のreviewを必須とすることで、グラデーション特有の複雑さに属人的とはいえ立ち向かうことができます。
ソフトウェア開発の営みは人によるものです。あらゆる面において人が介さぬ仕組みを構築することは理想ではありますが、人とシステムの相互作用によって目的のほとんどを達成できる事もあります。
分離プロジェクトの結果と反省
さて、これまで説明した手法を用いて、この分離プロジェクトは約半年で完了することができました。
実際に分離プロジェクトを進めた結果どうなったかを述べたいと思います。
まず、うまくいったこととして、今回の分離プロジェクトが何らかのuser visibleな機能開発のblockingになることは完全に回避できたことがあげられます。「Gatewayによる隔離」が想定通りうまく機能し、先にあげた課題であった「機能開発への影響」を最小限にできました。
また、分離プロジェクト進行中に、この分離プロジェクトを起因とするincidentが発生しなかったことも特筆すべき点でしょう。
一方でうまくいかなかったこととして、差分検証が機械的にできなかった点が挙げられます。特にリソース管理の状態の検証において、tachyonに公開する振る舞いとしては一貫しているものの内部のリソースのライフサイクルの差異により状態スナップショットに差異が発生する、と言ったことが頻発しました。ライフサイクル管理は適切に機能していたため、1つ1つのリソースに絞ってみれば問題はなく、安定した状態に帰着するのですが、状態スナップショットという1時点のリソースの集合としてみた場合に差分が発生し、それが問題ないことを検証するのに手間がかかりました。この点においては、当初より分離プロジェクト前後におけるライフサイクルの差異が想定以上に大きくなったとはいえ、大まかなスナップショットによる検証ではなく個々のリソースごとの差分検証をするべきだったかもしれません。
また、分離プロジェクト中に使用したfeature flagが多く、かつ依存関係を持つため、feature flag管理が大変だった事もあげられます。だいぶ人の記憶に頼った管理であったため、feature flagの依存関係をどのように記述し管理するかが大きな課題です。今の所、feature flagの数をより少なくする、feature flag間の依存関係を無くす or シンプルに保つ、feature flag名を分かりやすくする、以上の解決策は見出せていません。何か良いアイディアがあったら、教えていただきたいです :pray:
今後の展望
私たちはこれまでの経験から、技術的な複雑性とチームの拡大がもたらす課題を理解し、それに対応するための戦略を練り上げ、無事fermion分離プロジェクトを(いくつかの「諦め」ポイントは認めたものの)完了させることができました。
fermionの今後の展望としては、以下のような発展の方向性に注力していくことになります。
- リソース使用の最適化
- 社内ユーザーに向けたサポートレベルの向上
- 「諦め」ポイントの削減
- グローバル対応
clusterは発展途上のプラットフォームとして日進月歩の勢いで進化し続けています。これは一時的なものではなく、この先5年10年とプロダクトや環境の変化に適応し成長を続けるでしょう。そのためには開発組織もともにスケールアウトし続ける必要があります。さらに、仮想空間の日常を担うインフラとしての安定性と信頼性の向上も欠かせません。
これらの挑戦は簡単ではありませんが、自らの技術の限界を押し広げ、仮想空間での新しい可能性を探求することに情熱を感じる人にとっては、これらの挑戦は刺激的で意義深いものとなるでしょう。
クラスターでは、この挑戦的な環境で技術的な複雑性に果敢に取り組み、革新的なアプローチと創造的な問題解決能力を持つソフトウェアエンジニアを募集しています。
- clusterでは内部的に、クリエイターが作成した3D空間自体をworld、複数のクライアントの状態が同期されるworldの単位をroomと呼んでいます↩
- 増えるだけでなく、これからの変更を見据えた上で機能を削減した例 https://x.com/cluster_jp/status/1198904403991810048?s=20↩
- プロダクト状況や市場状況に大きく左右される領域のため、2023現在はtachyonの具体的な領域はあえて曖昧なままにしてあります。↩
- クラスターでは開発全体でDDDを採用しているわけではないですが、戦略的設計の1パターンとしてBounded Contextなどの概念を活用しています↩
- 将来的に同様のシステム分割をする際にはライブラリとして設計することになるかもしれません↩
- もちろん、この曖昧ポイントは徐々に削減していく予定です↩