
ソフトウェアエンジニアの浦川です。
clusterではサービス開発にfeature flagが活用されており、常時10+個程度のflagが並行して使われています。 これまでflagはgoのコードとしてハードコードされていたのですが、AWS AppConfigを利用してコードを修正することなく動的に変更できるようにしました。
昔のflag管理
ハードコードされたflagは1つのstructにまとめて定義されていて
// feature flagを集めたもの
type FeatureFlag struct {
IsAvatarXxx bool // アバターを良い感じにする
IsEventXxx bool // イベントを良い感じにする
// (大量のフラグ)
}
appが起動する環境(ENV環境変数により識別)によって適切なflagを含んだ設定情報を読みこむようになっていました。
// config_dev.go
var dev = Config{
Feature: FeatureFlag{
IsAvatarXxx: true,
IsEventXxx: true,
}
}
// config_stg.go
var stg = Config{
Feature: FeatureFlag{
IsAvatarXxx: true,
IsEventXxx: false,
}
}
// config_prd.go
var prd = Config{
Feature: FeatureFlag{
IsAvatarXxx: false,
IsEventXxx: false,
}
}
// main.go
var config Config
func main() {
env = os.Getenv("ENV")
switch env {
case "DEV": config = dev
case "STG": config = stg
case "PRD": config = prd
}
}
実装での利用イメージ
if config.Feature.IsEventXxx {
// onの場合
} else {
// offの場合
}
長らくこの方式で開発を続けていたのですが、徐々に不便さが目立つようになってきました。
まず、基本的にはepicごとにflagが作られるため、開発者の増加によって並行で進むepicが多くなり、結果flagも増えていきます。また、clusterはmonorepoで開発されておりflag定義は1箇所にあるので、開発者全員が同じファイルを変更することになりコンフリクトが頻発していました。 一番不便だったのは、flagの変更にソースコードの変更が伴うことです。ソースコードの変更が必要ということはプルリクエストを作成する、レビューを依頼する、CIを待つ...など芋蔓式に作業が発生してしまい、平時はあまり問題になりませんがインシデント対応等の緊急時にも同じだけ時間と手間がかかってしまうことを意味します。以前と比べclusterのコードベースはかなり大きなものとなってきたことでCIの所要時間が伸びてきたこと、flaky testの発生確率の増加してきたことも問題を大きくしていました。
機能リリースを安全におこなうためにfeature flagを導入しているのに、必要以上に手間がかかることで手順の漏れや作業のミスが発生しやすい状態となっていたことから、リリースなしでfeature flagを変更する仕組みを構築することで改善できるのではと考えました。
AWS AppConfigの導入
いくつか選択肢はあったのですが、検討した結果やりたいことに対して機能過多だったり労力が大きすぎたりしたため、一番ストレートに実現できそうなAWS AppConfigを利用することにしました。
大きな決め手はappconfig-agentがあったことです。 clusterのサーバー側はECSがメインであるため、導入の手間はほぼありませんでした。
ただ、SystemsManagerの障害やappconfig-agent自体の問題によりagentが正常に動いていない場合にどうするか、というのは懸念として何度も議論することになりました。
ECSではTaskDefinition内の設定(essential)で、コンテナが正常に動作していない場合にどうするかを指定できます。 appconfig-agentのessential=trueとすると、SystemsManagerやappconfig-agentの障害でサービス全体が停止する可能性があります。 一方でessential=falseだと、SystemsManagerにある設定を読みこめなかったり、appconfig-agentが不意に停止した場合でもサービスは動き続けるため一見安心に見えますが、全taskでflagをきちんと読みこめているのかの保証が難しくなります。つまり、taskAではflagX=trueで動いているが、taskBではflagX=falseで動いている、という可能性を排除できず、何らかの追加の監視が必須です。 appconfig-agentの出力するログを監視するなども検討しましたが、appconfig-agentの中身が分からない以上どの場合にどういうログが出るのかも分からないため大雑把に検知するぐらいしかできそうにありません。また、taskごとにflag状態が異なって動き続けた場合、機能によってはデータ不整合を引き起す危険もあり、インシデントそのものより事後対応が困難になることもありそうです。
以上をふまえ、clusterではECSでappconfig-agentを利用する場合はessential=trueとしています。 ただし、これはあくまで現時点の判断であって、将来的にappのSLOを満たすためには設定を変更する可能性はあり、運用を続けながら調整していきたいと考えています。
feature flagの管理
AWS AppConfigはなかなか多機能で、1つのconfigurationで複数の環境をサポートしていたり、flagの変更履歴やdeploy履歴を保存できるようになっており、チームによってはマネージドコンソールで直接管理する、というのも悪くないかもしれません。
clusterではメインで利用する開発者の扱いやすさを考慮して、下記のフローで運用しています。
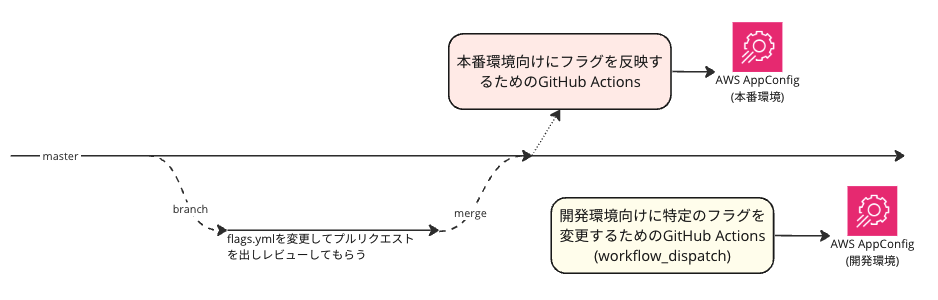 flagの変更をコミットしてもらうことで自然と変更履歴が残り、プルリクエストによるレビューも自然におこなえますし、GitHub Actionsを利用することで追加の手順なしでフラグを反映できるようにしています。
flagの変更をコミットしてもらうことで自然と変更履歴が残り、プルリクエストによるレビューも自然におこなえますし、GitHub Actionsを利用することで追加の手順なしでフラグを反映できるようにしています。
AWS AppConfigにはTerraform resourceがあるのでTerraformでの管理も検討しましたが、goのコードを自動生成したいという要件(後述)にフィットしなかったのと、force replaceなplanが作られてしまうため差分が分かり辛いこと、また、apply時にflag version が「1」のみにされてしまうことから、障害対応の手札を減らしてしまうのがイマイチだったので採用しませんでした。
開発環境についてはフラグの変更をレビューする意味は薄いため、敢えてプルリクエストを介さず変更できるようにしています。
feature flagの利用
appconfig-agentを利用することで、AWS AppConfig <-> ECS task間でフラグ状態は同期されるようになりましたが、app側から利用するにはもう一工夫必要になります。 appconfig-agentにより、appからはflag状態をlocalhostへのGETで参照できるようになるため、AWS AppConfigのことは意識しなくてもよくなりますが、appでflag分岐が必要になる都度HTTP requestを投げなければならないのは許容できないと思います。
このため、clusterでは「flag状態を読みこんでメモリ上にcacheしコード上から利用しやすくするためのコード」をflag.ymlから自動生成するようになっており、昔とほぼ変わらない使い勝手を実現しています。
if featureflag.IsEventXxx() {
// onの場合
} else {
// offの場合
}
もう1つ大事なのがテストです。 開発環境ではどのflagもtrueにすることが多いと思いますが、開発の進み方やスケジュール等により本番環境でflagをONにできる時期は異なるのが普通です。開発環境ではflagX=ON, flagY=ONだけど、本番ではflagX=ON, flagY=OFFというようなことも珍しくないため、flagの組み合わせでテストを動かしておけると安心です。しかし、flagが増えると取り得る組合せも莫大なものとなるためすべてをテストすることは不可能ですし効率もよくありません。そこで、flags.ymlは本番のflag状態であるという性質を利用し、CIではyamlからflag状態を読みこんだうえでテストをおこなうことで有効な組み合わせでのテストがおこなわれるようにしています。
まとめ
AWS AppConfigを利用したfeature flag管理をgo projectに導入した話を紹介しました。 flag変更のためだけのリリース作業が不要になり、面倒なコンフリクト解消作業が(ほぼ)不要となったことで、flagの管理上の問題はほぼ解消されました。また、GitHub Actionsなどを駆使し、ほとんど追加の手順なく開発者が自然と利用できるような仕組みにしたことで、安全に移行することもできたと思います。
現状はserver側のflag管理のみとしていますが、今後はclient app側も含めたサービス全体の統合的なflag管理をおこなえないかという検討も進めており、より安全な機能開発・リリースの仕組みを整えることで、安心してご利用いただけるプラットフォームを目指していきたいと思います。